


If python were to have a literal 'regular ex' it will be me, I keep running and coming back lol. But that would not be the aim of this article.
In this article, I would love to discuss my experience with Regular Expressions (REGEX).
Regular Expressions is a powerful tool in python used to precisely find patterns in text, this can come in useful when editing code, scraping the web and verifying user inputs.
I just concluded a project I found on this university's computer science course page where I am required to write a program that attempts to match lines of input against a list of regular expressions, for each line the name of the first matching pattern is printed, or unknown if no matching pattern is matched.
When run without any arguments, line will be read from standard input. If given a filename, lines will be read from that file. You can check out the project here.
I chose to work on this project because it will help me master Regular expressions especially for situations where I am working on getting user inputs, scraping the web and other related projects.
While working on this project I learnt that regular expressions and their symbols are constant across all programming languages, so there is no knowledge lost at any point. I learnt how to use a combination of these symbols to match patterns from this w3 schools python tutorial
After learning how to match patterns, some of the patterns I matched were:
Address:
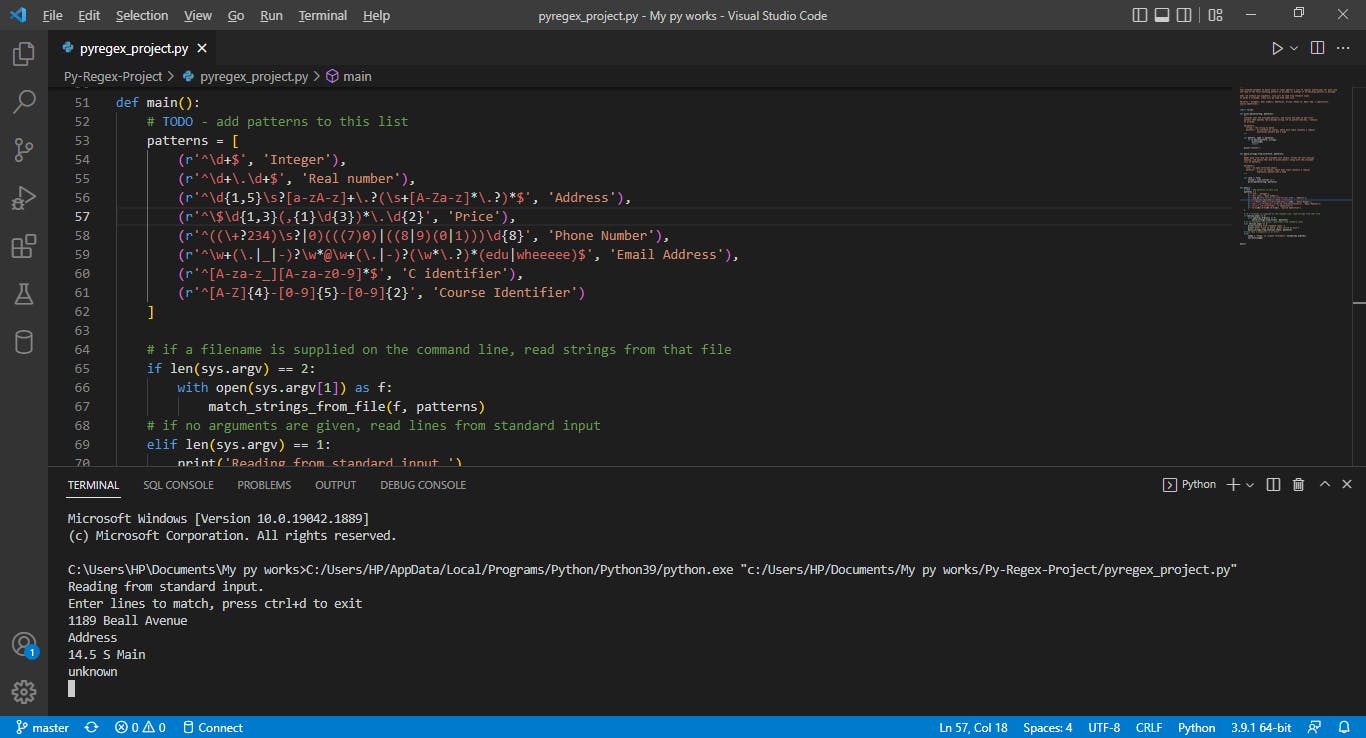
A valid address begins with a positive integer and is followed by one or more words or abbreviations. The words or abbreviations must consist of only letters from the English alphabet, may only contain a capital letter as the first letter, and may or may not end in a period.
The following are valid addresses:
- 189 Beall Avenue
- Main St.
- 56 elm
The following are not valid addresses:
- Eight fifty two North Washington
- 10 10 Springfield Lane
- 14.5 S Main
- 12 S.Main
The regular expression for the Address patterns above is - r'^\d{1,5}\s?[a-zA-z]+.?(\s+[A-Za-z].?)$'
Prices
A valid price is a numeric value using the US dollar sign. The number of cents is optional, but there must be two digits if the cents are shown. For prices above $999.99, there may optionally be a comma separating thousands, millions, etc.
The following are valid prices:
- $1
- $20
- $1.99
- $10.00
- $1500.50
- $2,000.99
- $1,234,567.89
The following are not valid prices:
- $1.9
- $10,23.4
The regular expression for the Price patterns above is - r'^\$\d{1,3}(,{1}\d{3})*.\d{2}'
Phone Number:
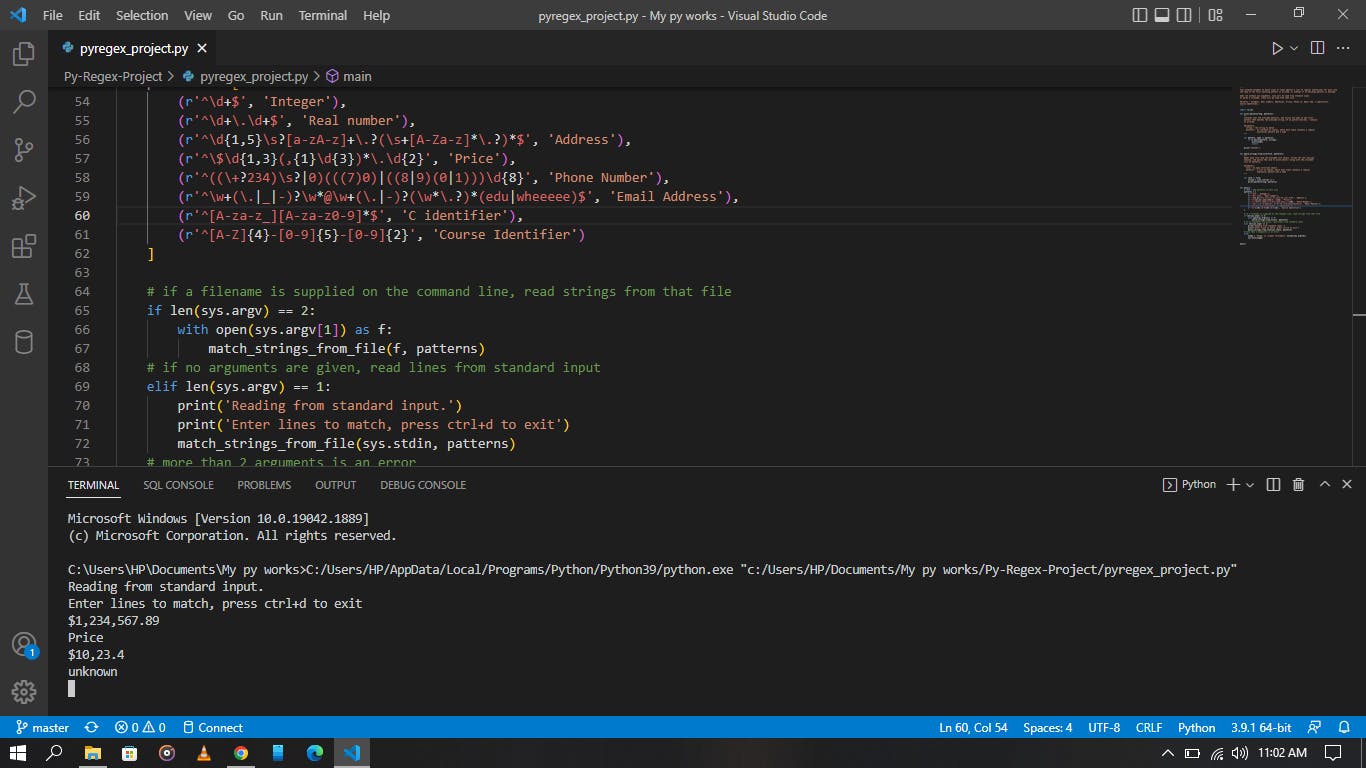
Since I am writing this from Nigeria, I wrote the regular expressions for Nigerian Phone numbers instead of the provided American numbers.
The following are valid Nigerian phone no formats:
- 07012345678
- 08012345678
- 09012345678
- 08112345678
- 09112345678
- +2347012345678
2348012345678
The regular expression for the Phone Number patterns above is - r'^((+?234)\s?|0)(((7)0)|((8|9)(0|1)))\d{8}'
Email Address:
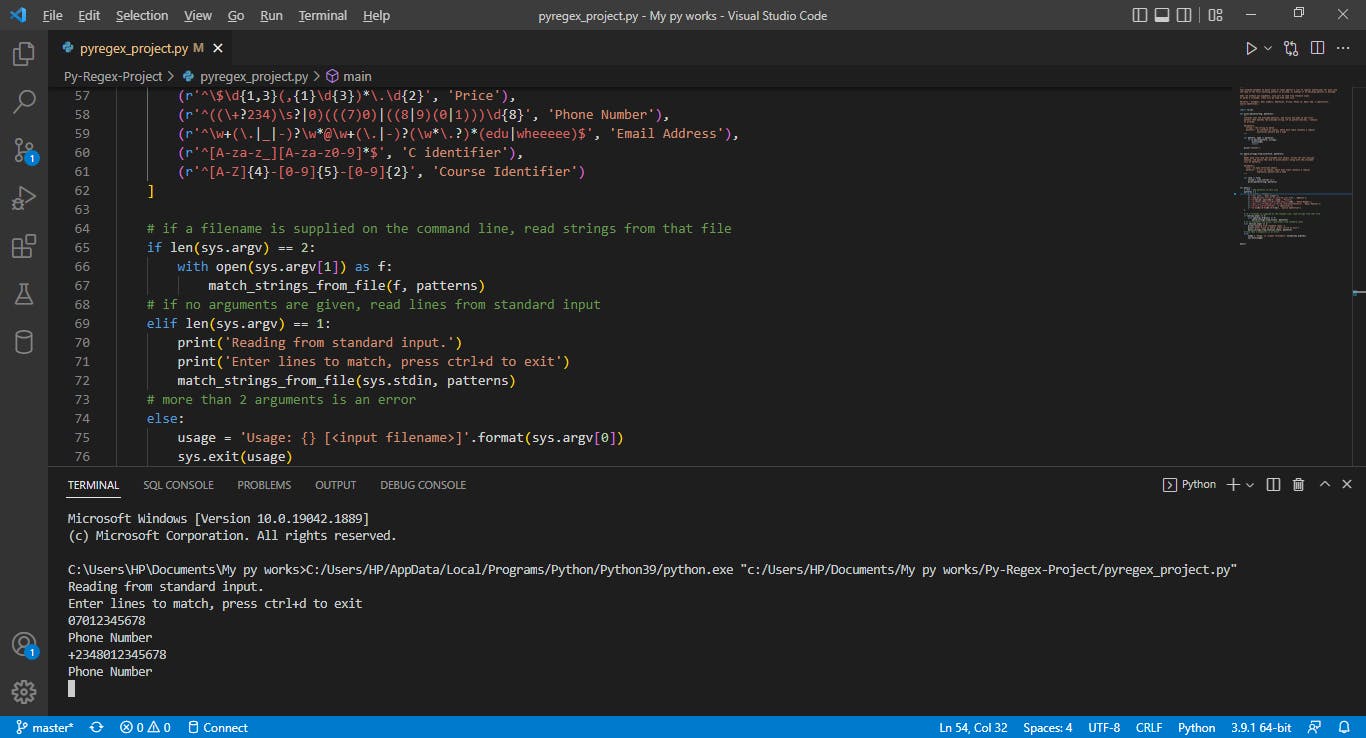
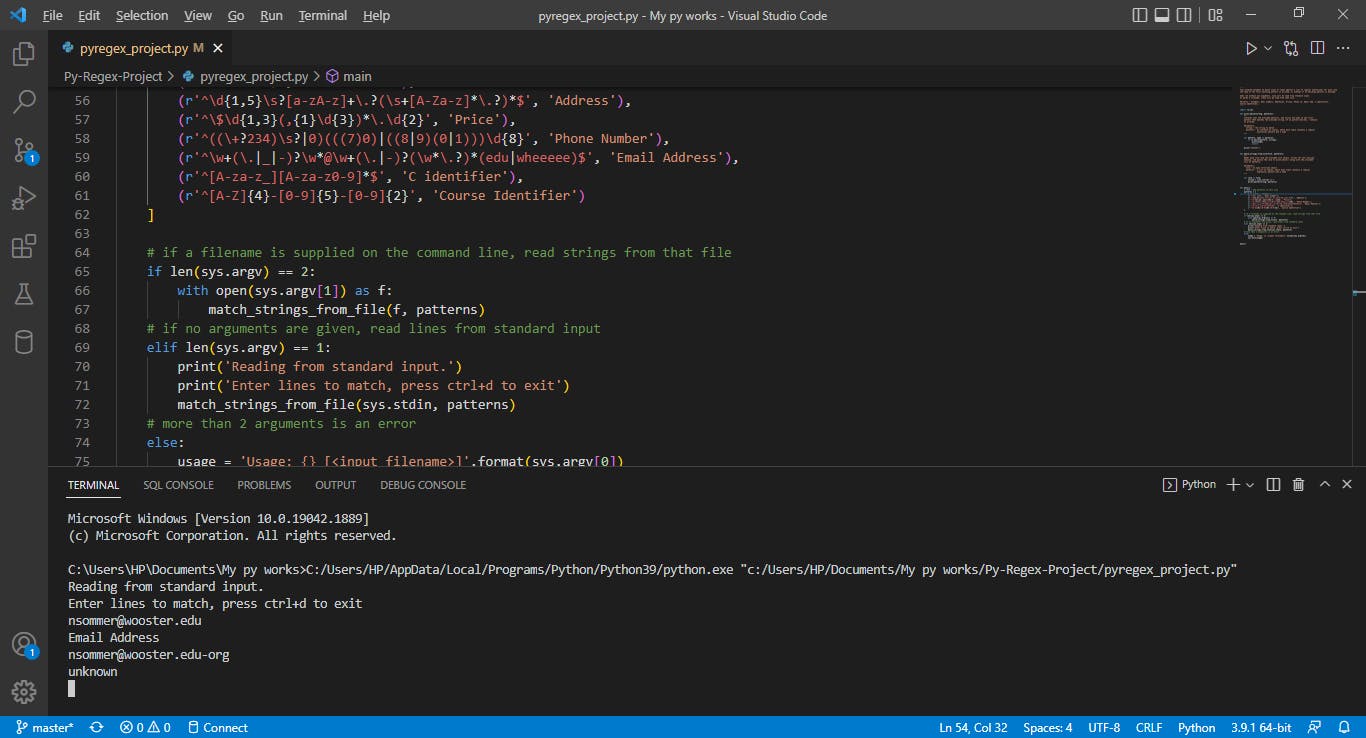
The first part of the email address is the username portion, and it must not contain whitespace or the @ symbol. The username portion is followed by the @ symbol. After the @ symbol is the domain, which does not contain any whitespace or the @ symbol. The domain contains two or more non-empty components which are separated by periods. The final component must consist of only letters from the English alphabet.
The following are valid email addresses:
- nsommer@wooster.edu
- n.sommer@cs.wooster.edu
- yippee_skippy@yee-haw.wheeeee
- fun-times@Taylor.hall.wooster.edu
The following are not valid email addresses:
- n@sommer@wooster.edu
- n sommer@wooster.edu
- nsommer@wooster..edu
- nsommer@wooster.edu-org
The regular expression for the Email address patterns above is - r'^\w+(.|_|-)?\w@\w+(.|-)?(\w.?)*(edu|wheeeee)$'
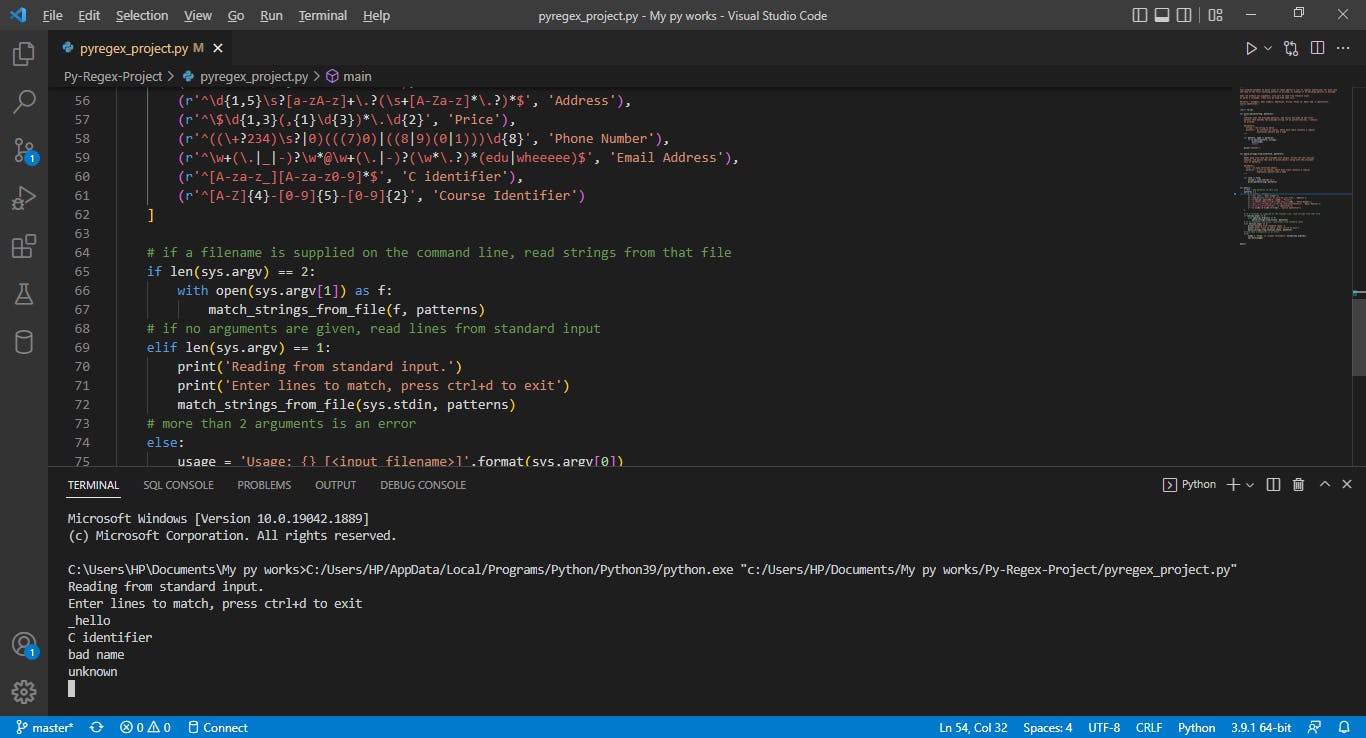
C identifier:
A C identifier is a name for a function, variable, etc. in a C program. A C identifier must contain only letters, digits, and underscores and the first character must be a letter or an underscore.
The following are valid C identifiers:
- x
- x1y2
- _hello
- funName
- FunName
The following are not valid C identifiers:
- 1x
- bad name
- !name
The regular expression for the C Identifiers patterns above is - r'^[A-za-z_][A-za-z0-9]*$'
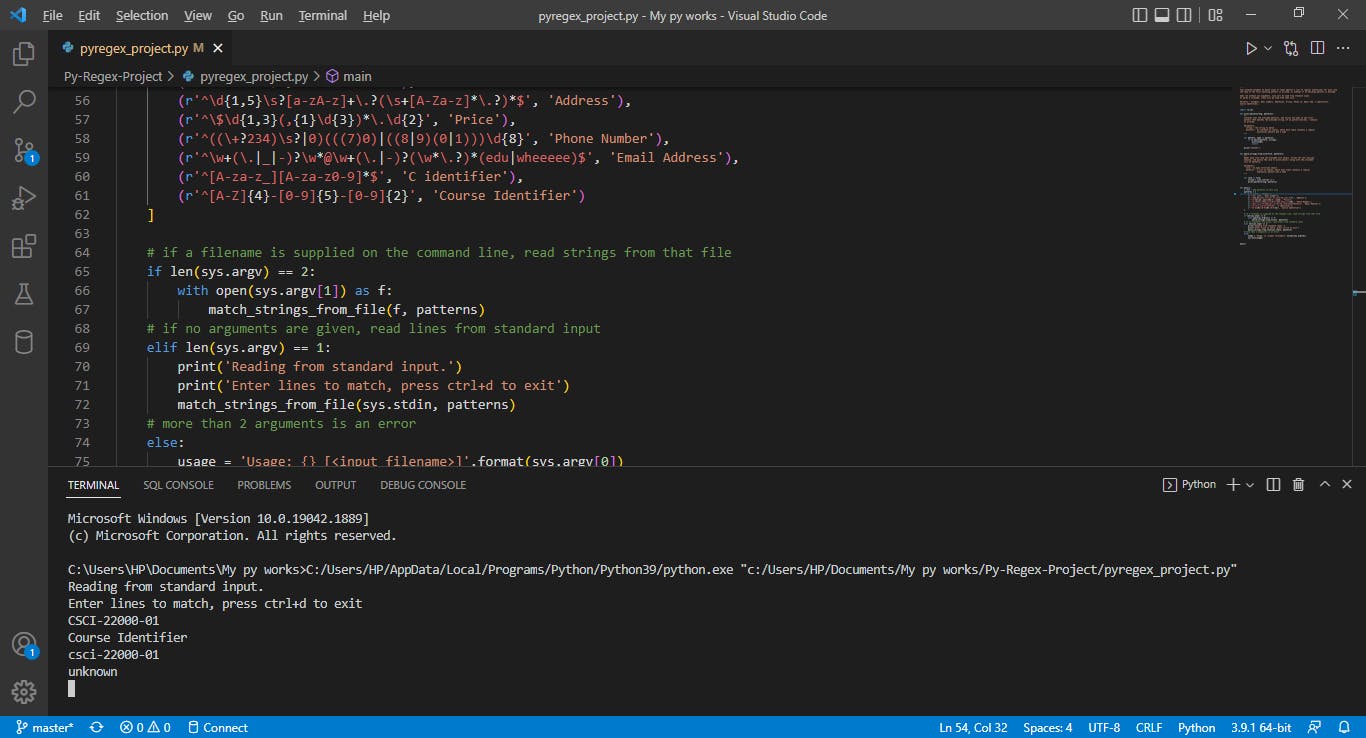
Course Identifier:
Courses at the College of Wooster are identified by four upper case letters identifying the department, five digits representing the course number, and two digits representing the section number, separated by hyphens. For example, the full identifier for this course is CSCI-22000-01.
The following are valid course identifiers:
- CSCI-22000-01
- MATH-11100-02
- FYSM-10100-33
- ABCD-12345-67
The following are not valid course identifiers:
- csci-22000-01
- CS 220
- CSCI 22000 01
The regular expression for the Course Identifier patterns above is - r'^[A-Z]{4}-[0-9]{5}-[0-9]{2}'
You can get more insight on this from the projects GitHub documentation
With the knowledge gained from working on this project, I can definitely work on other Regex related projects confidently.